Method
Overall Pipeline
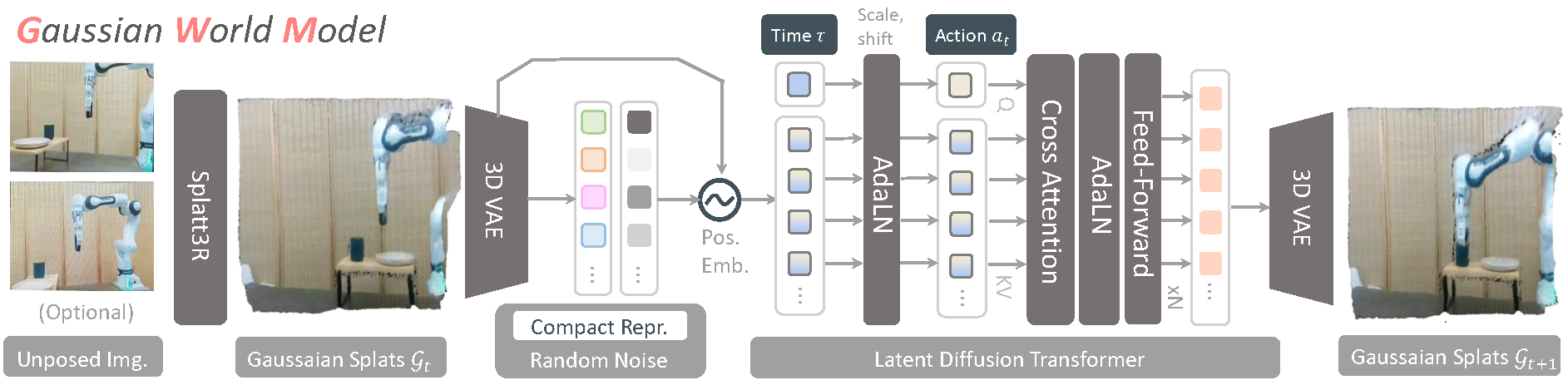
The overall pipeline of GWM, which primarily consists of a 3D variational encoder and a latent diffusion transformer. The 3D variational encoder embeds the Gaussian Splats estimated by a foundational reconstruction model to a compact latent space, and the diffusion transformer operates on the latent patches to interactively imagine the future Gaussian Splats conditioned on the robot action and denoising time step.